Microsoft SQL Server:
Microsoft SQL Server is a relational database management system (RDBMS). Applications and tools connect to a SQL Server instance or database, and communicate using Transact-SQL (T-SQL).
You can install SQL Server on Windows or Linux, deploy it in a Linux container, or deploy it on an Azure Virtual Machine.
SQL Server components and technologies:
Database Engine
The Database Engine is the core service for storing, processing, and securing data. The Database Engine provides controlled access and transaction processing to meet the requirements of the most demanding data consuming applications within your enterprise.
Integration Services
SQL Server Integration Services (SSIS) is a platform for building high performance data integration solutions, including packages that provide extract, transform, and load (ETL) processing for data warehousing.
Analysis Services
SQL Server Analysis Services (SSAS) is an analytical data platform and toolset for personal, team, and corporate business intelligence. Servers and client designers support traditional OLAP solutions, new tabular modeling solutions, as well as self-service analytics and collaboration using Power Pivot, Excel, and a SharePoint Server environment. Analysis Services also includes Data Mining so that you can uncover the patterns and relationships hidden inside large volumes of data.
Reporting Services
SQL Server Reporting Services (SSRS) delivers enterprise, Web-enabled reporting functionality. You can create reports that draw content from various data sources, publish reports in various formats, and centrally manage security and subscriptions.
Replication
SQL Server Replication is a set of technologies for copying and distributing data and database objects from one database to another, and then synchronizing between databases to maintain consistency. By using replication, you can distribute data to different locations and to remote or mobile users with local and wide area networks, dial-up connections, wireless connections, and the Internet.
Connecting to the Database Engine:
You connect to the Database Engine using a client tool or client library. Client tools run in a graphical user interface (GUI), or a command-line interface (CLI).
Example: SQL Server Management Studio (SSMS).
Connection to Database Engine:
When you connect to the Database Engine, you must provide an instance name (that is, the server or instance where the Database Engine is installed), a network protocol, and a connection port.
We are using SSMS, a GUI interface to connect with the database engine and creating , managing all database objects.
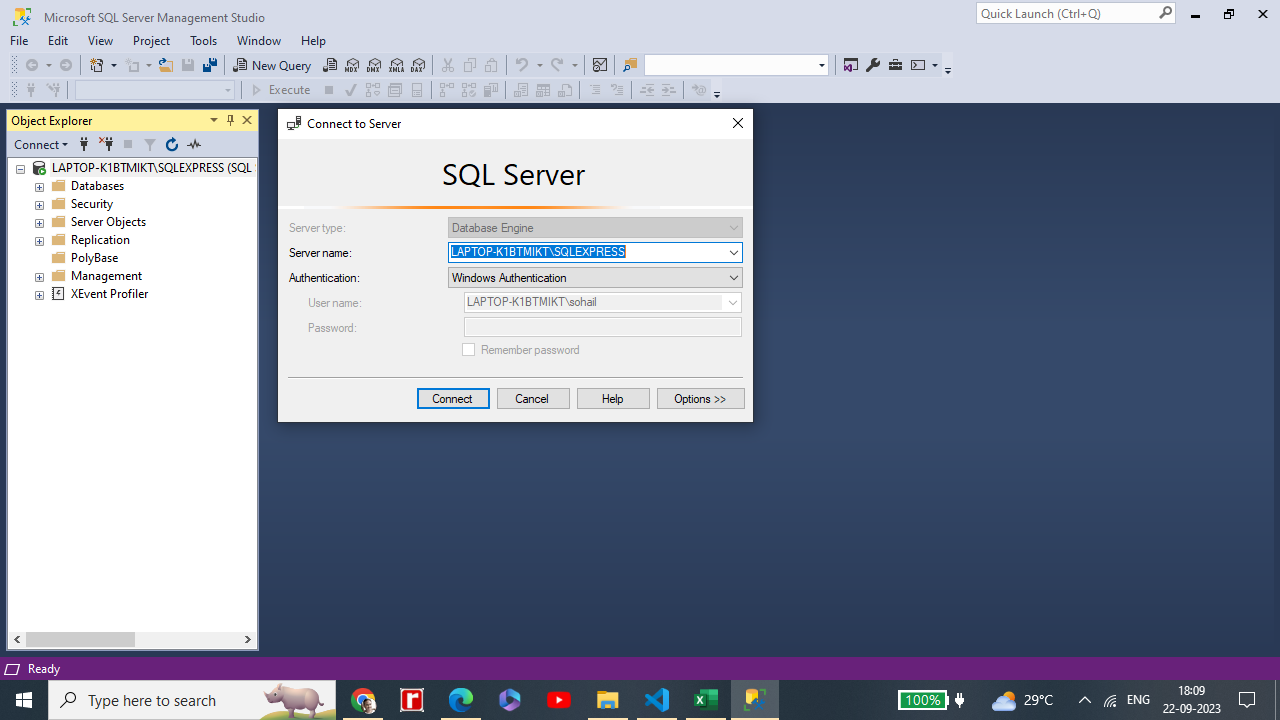
You need to provide server name and authentication to connect the Database Engine.
Network protocol considerations
For SQL Server on Windows, when you connect to an instance on the same machine as the client tool, and depending on which edition is installed, the default protocol may be configured with multiple protocols, including named pipes (np), TCP/IP (tcp), and shared memory (lpc).
Database:
A database in SQL Server is made up of a collection of tables that stores a specific set of structured data. A table contains a collection of rows, also referred to as records or tuples, and columns, also referred to as attributes. Each column in the table is designed to store a certain type of information, for example, dates, names, dollar amounts, and numbers.
A computer can have one or more than one instance of SQL Server installed. Each instance of SQL Server can contain one or many databases. Within a database, there are one or many object ownership groups called schemas. Within each schema there are database objects such as tables, views, and stored procedures. Some objects such as certificates and asymmetric keys are contained within the database, but are not contained within a schema.
SQL Server databases are stored in the file system in files. Files can be grouped into filegroups.
A user that has access to a database can be given permission to access the objects in the database. Though permissions can be granted to individual users, we recommend creating database roles, adding the database users to the roles, and then grant access permission to the roles. Granting permissions to roles instead of users makes it easier to keep permissions consistent and understandable as the number of users grow and continually change.
Most people who work with databases use the SQL Server Management Studio tool. The Management Studio tool has a graphical user interface for creating databases and the objects in the databases. Management Studio also has a query editor for interacting with databases by writing Transact-SQL statements.
System Databases: SQL Server includes the following system databases.
Master Database: Records all the system-level information for an instance of SQL Server.
Msdb Database: Is used by SQL Server Agent for scheduling alerts and jobs.
Model Database: s used as the template for all databases created on the instance of SQL Server. Modifications made to the model database, such as database size, collation, recovery model, and other database options, are applied to any databases created afterward.
Resource Database: Is a read-only database that contains system objects that are included with SQL Server. System objects are physically persisted in the Resource database, but they logically appear in the sys schema of every database.
Tempdb Database: Is a workspace for holding temporary objects or intermediate result sets.
Creating your own Database:
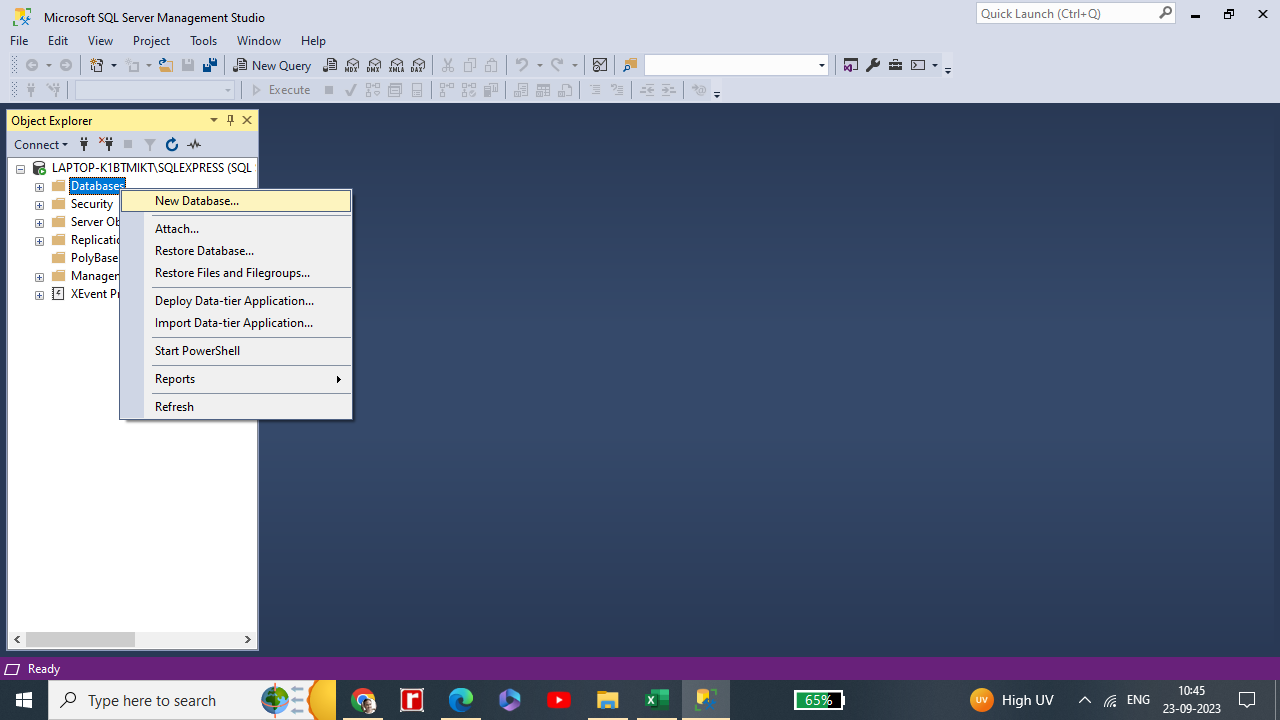
After connecting to the Database Engine right click on the database folder and click on the New Database option as shown below.
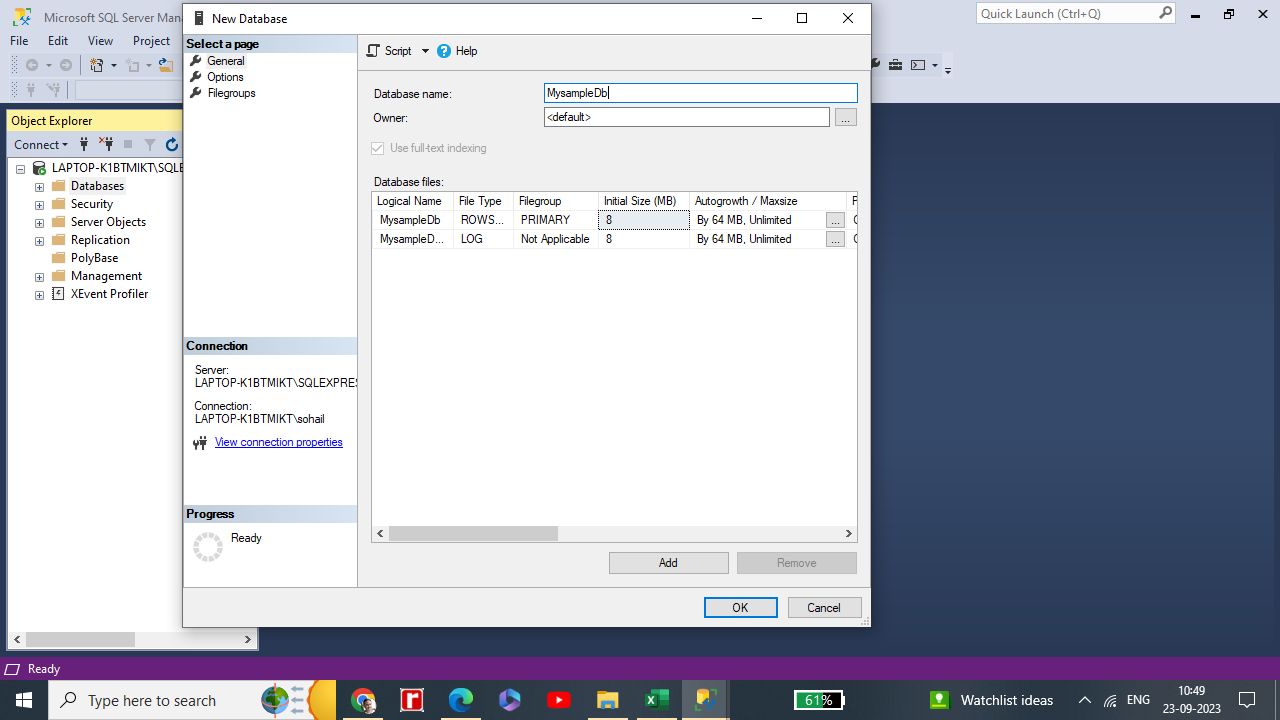
New Database wizard will open. Type your database name and Click the OK button.
Your Database is ready. In this example We have created a MysampleDb.
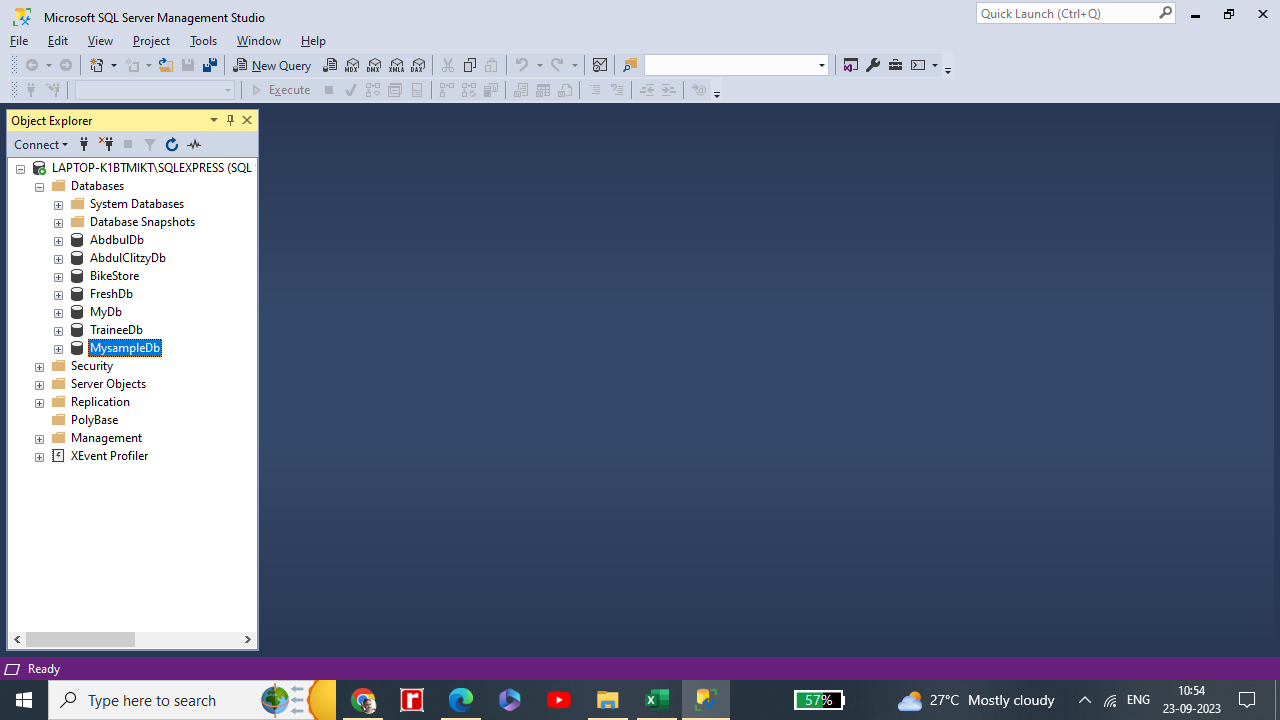
Now our database mySampledb is ready and we need to create a schema or directly a table for this database.
Creating a table:
You can create a new table, name it, and add it to an existing database, by using the table designer in SQL Server Management Studio (SSMS), or Transact-SQL.
Use Transact-SQL
In Object Explorer, connect to an instance of Database Engine.
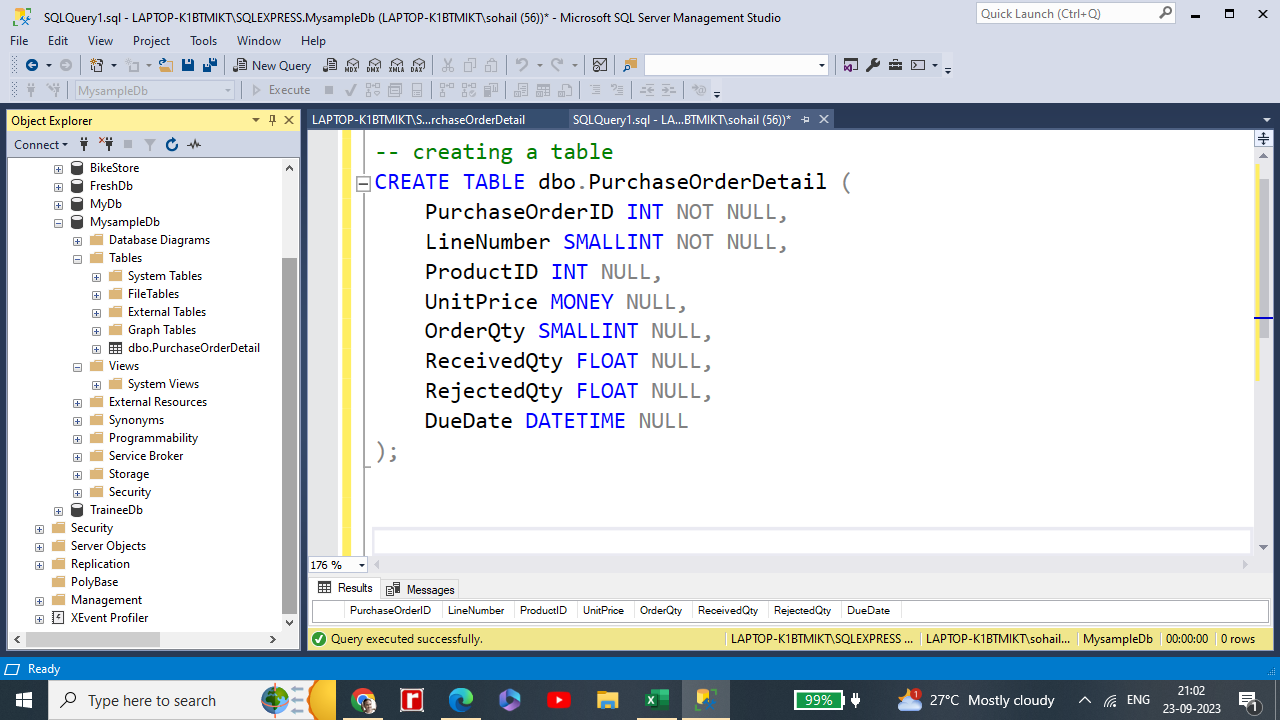
On the Standard bar, select New Query. New query editor will open . Type the following code to create the table PurchaseOrderDetails.
CREATE TABLE dbo.PurchaseOrderDetail (
PurchaseOrderID INT NOT NULL,
LineNumber SMALLINT NOT NULL,
ProductID INT NULL,
UnitPrice MONEY NULL,
OrderQty SMALLINT NULL,
ReceivedQty FLOAT NULL,
RejectedQty FLOAT NULL,
DueDate DATETIME NULL
);
Syntax :
CREATE TABLE
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
( { <column_definition> } [ ,... n ] )
[ ; ]
PurchaseOrderTable created in the dbo schema just like shown below.
Data types:
There are different data types available for the columns according to the need we can choose relevant data type for specific columns.
For text data we can choose varchar,char, text data types.
For numbers we can opt for int, float, numeric, decimal and many more.
We can also have data types - binary, image, datetime for specific specialised needs of the data storage.
Create table:
CREATE TABLE dbo.Products
(ProductID int PRIMARY KEY NOT NULL,
ProductName varchar(25) NOT NULL,
Price money NULL,
ProductDescription varchar(max) NULL)
GO
Inserting data in the Table:
you have created the Products table, you are ready to insert data into the table by using the INSERT statement.
The basic syntax is: INSERT, table name, column list, VALUES, and then a list of the values to be inserted.
-- Standard syntax ( commented this line with --)
INSERT dbo.Products (ProductID, ProductName, Price, ProductDescription)
VALUES (1, 'Clamp', 12.48, 'Workbench clamp')
GO
Another way to insert column values into the table:
-- Skipping the column list, but keeping the values in order
INSERT dbo.Products
VALUES (75, 'Tire Bar', NULL, 'Tool for changing tires.')
GO
Updating / changing data :
Update statement is used to change or update the data in the table based on the condition assigned to the ‘where’ clause.
Note: If you don't provide where clause condition then the change/ update will apply to all the rows of the table.
UPDATE dbo.Products
SET ProductName = 'Flat Head Screwdriver'
WHERE ProductID = 50
GO
Read the Data from the Table:
Use the SELECT statement to read the data in a table. The SELECT statement is one of the most important Transact-SQL statements, and there are many variations in the syntax.
-- The basic syntax for reading data from a single table
SELECT ProductID, ProductName, Price, ProductDescription
FROM dbo.Products
GO
-- Returns all columns in the table
-- Does not use the optional schema, dbo
SELECT * FROM Products
GO
You can omit columns that you don't want to return. The columns are returned in the order that they are listed.
-- Returns only two of the records in the table
SELECT ProductID, ProductName, Price, ProductDescription
FROM dbo.Products
WHERE ProductID < 60
GO
You can work with the values in the columns as they are returned. The following example performs a mathematical operation on the Price column. Columns that have been changed in this way don't have a name unless you provide one by using the AS keyword.
-- Returns ProductName and the Price including a 7% tax
-- Provides the name CustomerPays for the calculated column
SELECT ProductName, Price * 1.07 AS CustomerPays
FROM dbo.Products
GO
Working with Functions:
CONCAT() :This function returns a string resulting from the concatenation, or joining, of two or more string values in an end-to-end manner.
Syntax:
CONCAT ( string_value1, string_value2 [, string_valueN ] )
Examples:
SELECT CONCAT ( 'Happy ', 'Birthday ', 11, '/', '25' ) AS Result;
Result
-------------------------
Happy Birthday 11/25
(1 row(s) affected)
Using concat () with null values:
CREATE TABLE #temp (
emp_name NVARCHAR(200) NOT NULL,
emp_middlename NVARCHAR(200) NULL,
emp_lastname NVARCHAR(200) NOT NULL
);
INSERT INTO #temp VALUES( 'Munna', NULL, 'Bhai' );
SELECT CONCAT( emp_name, emp_middlename, emp_lastname ) AS Result
FROM #temp
Result
------------------
MunnaBhai
(1 row(s) affected)
REPLACE(): Replaces all occurrences of a specified string value with another string value.
Syntax:
REPLACE ( string_expression , string_pattern , string_replacement )
Example:
SELECT REPLACE('abcdefghicde','cde','xxx');
GO
------------
abxxxfghixxx
(1 row(s) affected)
REVERSE(): Returns the reverse order of a string value.
Syntax: REVERSE ( string_expression )
Example:
SELECT FirstName, REVERSE(FirstName) AS Reverse
FROM Person.Person
WHERE BusinessEntityID < 5
ORDER BY FirstName;
GO
FirstName Reverse
-------------- --------------
Ken neK
Rob boR
Roberto otreboR
Terri irreT
(4 row(s) affected)
DateTime functions:
SYSDATETIME SYSDATETIME ( ) Returns a datetime2(7) value containing the date and time of the computer on which the instance of SQL Server runs. The returned value doesn't include the time zone offset.
SYSDATETIMEOFFSET SYSDATETIMEOFFSET ( ) Returns a datetimeoffset(7) value containing the date and time of the computer on which the instance of SQL Server runs. The returned value includes the time zone offset.
Example:
SELECT SYSDATETIME()
,SYSDATETIMEOFFSET()
,SYSUTCDATETIME()
,CURRENT_TIMESTAMP
,GETDATE()
,GETUTCDATE();
/* Returned:
SYSDATETIME() 2007-04-30 13:10:02.0474381
SYSDATETIMEOFFSET()2007-04-30 13:10:02.0474381 -07:00
SYSUTCDATETIME() 2007-04-30 20:10:02.0474381
CURRENT_TIMESTAMP 2007-04-30 13:10:02.047
GETDATE() 2007-04-30 13:10:02.047
GETUTCDATE() 2007-04-30 20:10:02.047
*/
Conversion functions support data type casting and conversion:
CAST() & CONVERT() : These functions convert an expression of one data type to another.
Syntax:
CAST ( expression AS data_type [ ( length ) ] )
Syntax:
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
Examples:
SELECT CAST(10.6496 AS INT) AS trunc1,
CAST(-10.6496 AS INT) AS trunc2,
CAST(10.6496 AS NUMERIC) AS round1,
CAST(-10.6496 AS NUMERIC) AS round2;
Result:
trunc1 trunc2 round1 round2
10 -10 11 -11
Example:
SELECT CONVERT (date, SYSDATETIME())
,CONVERT (date, SYSDATETIMEOFFSET())
,CONVERT (date, SYSUTCDATETIME())
,CONVERT (date, CURRENT_TIMESTAMP)
,CONVERT (date, GETDATE())
,CONVERT (date, GETUTCDATE());
GO
Result:
2023-09-25 2023-09-25 2023-09-25 2023-09-25 2023-09-25 2023-09-25
PARSE(): Returns the result of an expression, translated to the requested data type in SQL Server.
Syntax:
PARSE ( string_value AS data_type [ USING culture ] )
Example:
SELECT PARSE('Monday, 13 December 2010' AS datetime2 USING 'en-US') AS Result;
Result
---------------
2010-12-13 00:00:00.0000000
(1 row(s) affected)
-- The English language is mapped to en-US specific culture
SET LANGUAGE 'English';
SELECT PARSE('12/16/2010' AS datetime) AS Result;
Go
Result
2010-12-16 00:00:00.000
TRY_CONVERT(): Returns a value cast to the specified data type if the cast succeeds; otherwise, returns null.
Syntax:
TRY_CONVERT ( data_type [ ( length ) ], expression [, style ] )
Example:
SET DATEFORMAT mdy;
SELECT TRY_CONVERT(datetime2, '11/28/2021') AS Result;
GO
Result
2021-11-28 00:00:00.0000000
TRY_PARSE(): Returns the result of an expression, translated to the requested data type, or null if the cast fails in SQL Server. Use TRY_PARSE only for converting from string to date/time and number types.
Syntax:
TRY_PARSE ( string_value AS data_type [ USING culture ] )
Example:
SELECT TRY_PARSE('Jabberwokkie' AS datetime2 USING 'en-US') AS Result;
Result
---------------
NULL
(1 row(s) affected)
SET DATEFORMAT mdy;
SELECT TRY_CONVERT(datetime2, '11/28/2021') AS Result;
GO
Result
2021-11-28 00:00:00.0000000
SELECT TRY_PARSE('10/20/2022' AS datetime USING 'en-US') AS Result;
GO
Result
2022-10-20 00:00:00.000
POWER(): Returns the value of the specified expression to the specified power.
Syntax:
POWER ( float_expression , y )
The following example demonstrates raising a number to the power of 3 (the cube of the number).
DECLARE @input1 FLOAT;
DECLARE @input2 FLOAT;
SET @input1= 2;
SET @input2 = 2.5;
SELECT POWER(@input1, 3) AS Result1, POWER(@input2, 3) AS Result2;
Result1 Result2
---------------------- ----------------------
8 15.625
(1 row(s) affected)
ROUND(): Returns a numeric value, rounded to the specified length or precision.
Syntax:
ROUND ( numeric_expression , length [ ,function ] )
Example:
SELECT ROUND(123.9994, 3), ROUND(123.9995, 3);
GO
----------- -----------
123.9990 124.0000
CEILING(): This function returns the smallest integer greater than, or equal to, the specified numeric expression.
Syntax:
CEILING ( numeric_expression )
Example:
SELECT CEILING($123.45), CEILING($-123.45), CEILING($0.0);
GO
--------- --------- -------------------------
124.00 -123.00 0.00
(1 row(s) affected)
FLOOR(): Returns the largest integer less than or equal to the specified numeric expression.
Syntax:
FLOOR ( numeric_expression )
Example:
SELECT FLOOR(123.45), FLOOR(-123.45), FLOOR($123.45);
--------- --------- -----------
123 -124 123.0000
EXP(): Returns the exponential value of the specified float expression.
Syntax:
EXP ( float_expression )
Example:
SELECT EXP(2)
(No column name)
7.38905609893065
DECLARE @var FLOAT
Declare @Result varchar(200)
SET @var = 10
SELECT 'The EXP of the variable is: ' + CONVERT(VARCHAR, EXP(@var)) as Result;
Result
The EXP of the variable is: 22026.5
To view a list of databases on an instance of SQL Server type the following script:
SELECT name, database_id, create_date
FROM sys.databases;
GO
master 1 2003-04-08 09:13:36.390
tempdb 2 2023-09-22 17:03:20.577
model 3 2003-04-08 09:13:36.390
msdb 4 2017-08-22 19:39:22.887
MyDb 5 2019-09-07 11:18:49.360
AbdulClitzyDb 6 2020-04-04 13:01:03.263
FreshDb 7 2021-01-10 23:31:41.360
AbdbulDb 8 2022-03-04 11:04:45.060
BikeStore 9 2022-03-10 15:41:59.113
TraineeDb 10 2022-04-14 10:49:15.570
MysampleDb 11 2023-09-23 10:52:44.950
Schema:
A schema contains database objects such as tables,views & stored procedures. A schema owner can be database user, database role or application role.
Creating schema.
--creating a schema on a database
CREATE SCHEMA Chains;
GO
-- creating a table in the schema
CREATE TABLE Chains.Sizes (ChainID int, width dec(10,2));
Changing column name: Use sp_rename stored procedure to rename a column.
Syntax: EXEC sp_rename ‘tablename.existingColumn’, ‘newColumnName’, ‘COLUMN’;
EXEC sp_rename 'dbo.ErrorLog.ErrorTime', 'ErrorDateTime', 'COLUMN';
Copying columns from one table to another table:
USE AdventureWorks2022;
GO
CREATE TABLE dbo.EmployeeSales
( BusinessEntityID varchar(11) NOT NULL,
SalesYTD money NOT NULL
);
GO
INSERT INTO dbo.EmployeeSales
SELECT BusinessEntityID, SalesYTD
FROM Sales.SalesPerson;
GO
Primary key:
A table typically has a column or combination of columns that contain values that uniquely identify each row in the table. This column, or columns, is called the primary key (PK) of the table and enforces the entity integrity of the table. Because primary key constraints guarantee unique data, they are frequently defined on an identity column.
When you specify a primary key constraint for a table, the Database Engine enforces data uniqueness by automatically creating a unique index for the primary key columns. This index also permits fast access to data when the primary key is used in queries. If a primary key constraint is defined on more than one column, values may be duplicated within one column, but each combination of values from all the columns in the primary key constraint definition must be unique.
A table can contain only one primary key constraint.
If clustered or nonclustered is not specified for a primary key constraint, clustered is used if there is no clustered index on the table.
All columns defined within a PRIMARY KEY constraint must be defined as NOT NULL
Create a primary key in a new table:
Example:
CREATE TABLE Production.TransactionHistoryArchive1
(
TransactionID int IDENTITY (1,1) NOT NULL
, CONSTRAINT PK_TransactionHistoryArchive1_TransactionID PRIMARY KEY CLUSTERED (TransactionID)
);
Create a primary key with non-clustered index in a new table:
Example:
-- Create table to add the clustered index
CREATE TABLE Production.TransactionHistoryArchive1
(
CustomerID uniqueidentifier DEFAULT NEWSEQUENTIALID()
, TransactionID int IDENTITY (1,1) NOT NULL
, CONSTRAINT PK_TransactionHistoryArchive1_CustomerID PRIMARY KEY NONCLUSTERED (CustomerID)
)
;
-- Now add the clustered index
CREATE CLUSTERED INDEX CIX_TransactionID ON Production.TransactionHistoryArchive1 (TransactionID);
Create a primary key in an existing table:
Example:
ALTER TABLE Production.TransactionHistoryArchive
ADD CONSTRAINT PK_TransactionHistoryArchive_TransactionID PRIMARY KEY CLUSTERED (TransactionID);
Foreign Key:
Foreign key create a relationship between two tables when you want to associate rows of one table with rows of another table.
FOREIGN KEY constraints can reference another column in the same table, and is referred to as a self-reference.
A FOREIGN KEY constraint specified at the column level can list only one reference column. This column must have the same data type as the column on which the constraint is defined.
A FOREIGN KEY constraint specified at the table level must have the same number of reference columns as the number of columns in the constraint column list. The data type of each reference column must also be the same as the corresponding column in the column list.
The following example creates a table and defines a foreign key constraint on the column TempID that references the column SalesReasonID in the Sales.SalesReason table in the AdventureWorks database. The ON DELETE CASCADE and ON UPDATE CASCADE clauses are used to ensure that changes made to Sales.SalesReason table are automatically propagated to the Sales.TempSalesReason table.
CREATE TABLE Sales.TempSalesReason
(
TempID int NOT NULL, Name nvarchar(50)
, CONSTRAINT PK_TempSales PRIMARY KEY NONCLUSTERED (TempID)
, CONSTRAINT FK_TempSales_SalesReason FOREIGN KEY (TempID)
REFERENCES Sales.SalesReason (SalesReasonID)
ON DELETE CASCADE
ON UPDATE CASCADE
);
Create a foreign key in an existing table:
The following example creates a foreign key on the column TempID and references the column SalesReasonID in the Sales.SalesReason table in the AdventureWorks database.
ALTER TABLE Sales.TempSalesReason
ADD CONSTRAINT FK_TempSales_SalesReason FOREIGN KEY (TempID)
REFERENCES Sales.SalesReason (SalesReasonID)
ON DELETE CASCADE
ON UPDATE CASCADE;
Unique & Check Constraints:
UNIQUE constraints and CHECK constraints are two types of constraints that can be used to enforce data integrity in SQL Server tables. These are important database objects.
Unique constraint automatically creates a corresponding unique index.
When a UNIQUE constraint is added to an existing column or columns in the table, by default, the Database Engine examines the existing data in the columns to make sure all values are unique. If a UNIQUE constraint is added to a column that has duplicate values, the Database Engine returns an error and does not add the constraint.
Example:
USE AdventureWorks2022;
GO
CREATE TABLE Production.TransactionHistoryArchive4
(
TransactionID int NOT NULL,
CONSTRAINT AK_TransactionID UNIQUE(TransactionID)
);
GO
To create a unique constraint on an existing table;
USE AdventureWorks2022;
GO
ALTER TABLE Person.Password
ADD CONSTRAINT AK_Password UNIQUE (PasswordHash, PasswordSalt);
GO
Check Constraint:
You can create a check constraint in a table to specify the data values that are acceptable in one or more columns.
Example:
ALTER TABLE dbo.DocExc
ADD ColumnD int NULL
CONSTRAINT CHK_ColumnD_DocExc
CHECK (ColumnD > 10 AND ColumnD < 50);
GO
To test the constraint, first add values that will pass the check constraint.
INSERT INTO dbo.DocExc (ColumnD) VALUES (49);
Next, attempt to add values that will fail the check constraint.
INSERT INTO dbo.DocExc (ColumnD) VALUES (55);
Working with JOINS:
By using joins, you can retrieve data from two or more tables based on logical relationships between the tables. Joins indicate how SQL Server should use data from one table to select the rows in another table.
A join condition defines the way two tables are related in a query by:
Specifying the column from each table to be used for the join. A typical join condition specifies a foreign key from one table and its associated key in the other table.
Specifying a logical operator (for example, = or <>,) to be used in comparing values from the columns.
Joins are expressed logically using the following Transact-SQL syntax:
INNER JOIN
LEFT [ OUTER ] JOIN
RIGHT [ OUTER ] JOIN
FULL [ OUTER ] JOIN
CROSS JOIN
Inner joins can be specified in either the FROM or WHERE clauses. Outer joins and cross joins can be specified in the FROM clause only. The join conditions combine with the WHERE and HAVING search conditions to control the rows that are selected from the base tables referenced in the FROM clause.
Specifying the join conditions in the FROM clause helps separate them from any other search conditions that may be specified in a WHERE clause, and is the recommended method for specifying joins. A simplified ISO FROM clause join syntax is:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
Example:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Example with table aliases:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
The following query contains the same join condition specified in the WHERE clause:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
-------------------
AdventureWorks sample databases:
Download AdventureWorks sample databases, and restore them to SQL Server.
Go to the below url to download AdventureWorks sample databases.
You can use the .bak file to restore your sample database to your SQL Server instance.
To restore your database in SSMS, follow these steps:
Download the appropriate .bak file from one of links provided in the download backup files section.
Move the .bak file to your SQL Server backup location. This varies depending on your installation location, instance name and version of SQL Server. For example, the default location for a default instance of SQL Server 2019 (15.x) is:
C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\Backup.
Open SSMS and connect to your SQL Server instance.
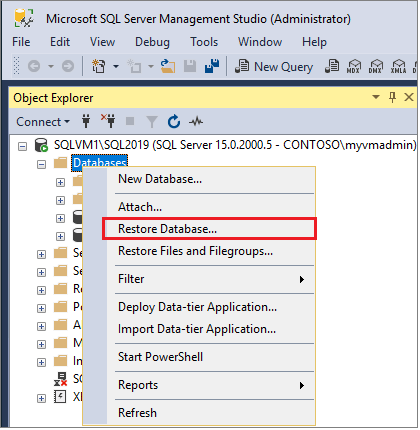
Right-click Databases in Object Explorer > Restore Database... to launch the Restore Database wizard.
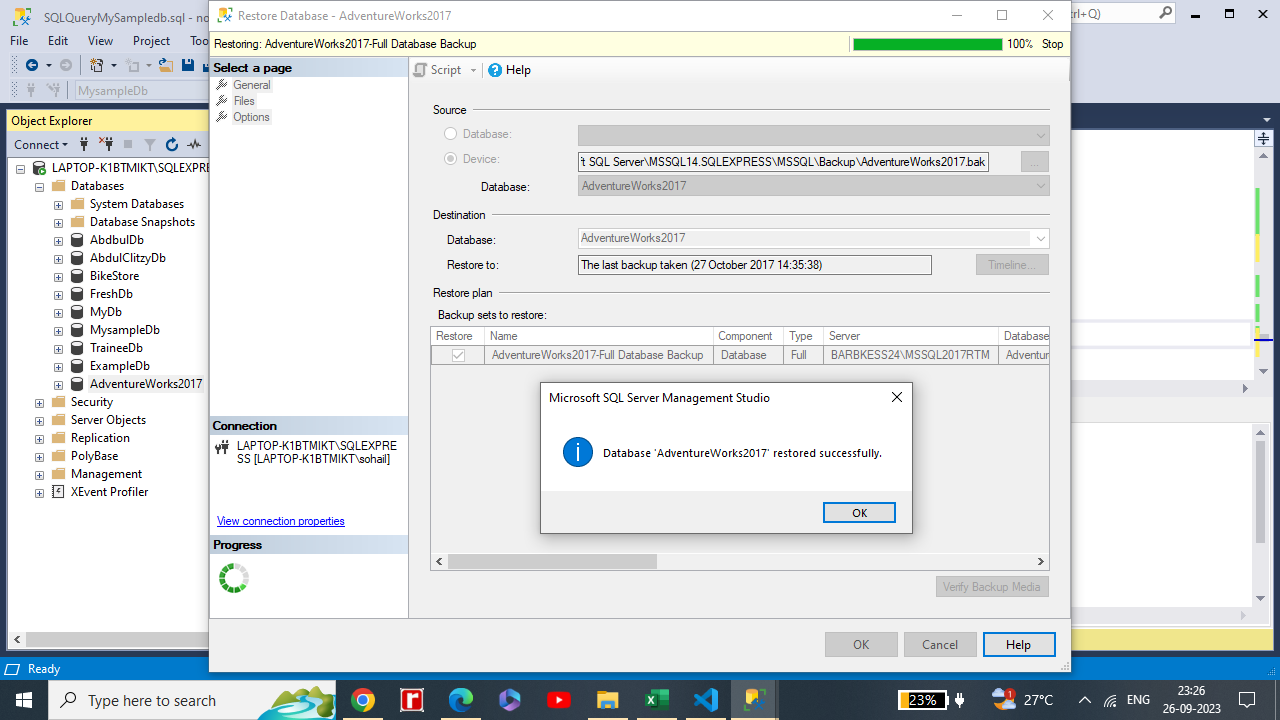
Select Device and then select the ellipses (...) to choose a device.
Select Add and then choose the .bak file you recently moved to the backup location. If you moved your file to this location but you're not able to see it in the wizard, this typically indicates a permissions issue - SQL Server or the user signed into SQL Server doesn't have permission to this file in this folder.
Select OK to confirm your database backup selection and close the Select backup devices window.
Check the Files tab to confirm the Restore as location and file names match your intended location and file names in the Restore Database wizard.
Select OK to restore your database.

Comments
Post a Comment